
JavaScript is currently the most widely used programming language, with 62.3% of developers worldwide using it. It has evolved from simply adding interactivity to becoming the backbone of complex, dynamic web applications. And with that, new challenges arise for Javascript SEO.
Because of the constant updates in the tech world, understanding how to optimize JavaScript for search engines is now essential. This guide will walk you through the key aspects of JavaScript SEO, ensuring your content is both user-friendly and easily accessible to search engines.
But before that, let’s start by exploring what JavaScript is and why it’s so important for your website.
What is JavaScript?
JavaScript is a widely used programming language that is critical in web development. This language allows you to implement complex features on web pages.
It’s part of the three core web technologies which include:
- HTML or HyperText Markup Language: The descriptive language that specifies webpage structure.
- CSS (Cascading Style Sheets): A declarative language that controls how webpages look in the browser.
- JavaScript: A scripting language that allows you to generate dynamically updated information, manage multimedia, and animate graphics.
So Javascript is more likely involved if you see things like animated 2D/3D graphics and interactive maps on a website.
Simply put, think of JavaScript as the engine that powers a website’s interactivity and dynamic features. If a website were a car, HTML would be the frame and structure. CSS would be the paint and design. And JavaScript would be the engine that makes everything move and respond to your actions.
How JavaScript is Used
JavaScript is unique in that it can be used both on the client side or in the user’s browser and on the server or web server.
On the client side, JavaScript is often used to create interactive features on web pages like buttons that do something when clicked, dynamic forms that update based on user input, or content that updates without needing to reload the page.
On the server side, thanks to environments like Node.js, JavaScript can handle tasks traditionally managed by other programming languages. This includes managing databases, handling requests from web browsers, and serving dynamic content.
This allows developers to use a single language across the entire web development stack, streamlining development processes and improving collaboration.
Common Uses in Web Development
One of JavaScript’s greatest strengths is its versatility. Here are some common ways it’s used in web development:
1. Interactivity: This programming language enables websites to be more interactive. For example, it can be used to create animations, handle form submissions, and validate user inputs in real-time.
2. Dynamic Content: It allows websites to update content dynamically. For instance, social media feeds that update automatically or interactive maps that respond to user input are powered by JavaScript.
3. Full-Stack Development: With frameworks like Node.js, JavaScript is also used on the server side. It enables developers to build the entire application, from the front-end user interface to the back-end database interactions, using a single language.
4. Game Development: While not as common for large-scale games, JavaScript is often used for browser-based games and simple mobile games, particularly those that can be played directly within a web browser.
5. Real-Time Applications: JavaScript is integral to the development of real-time applications like chat apps or live collaboration tools, where updates and changes need to be reflected instantly across all users.
We’ve already covered what JavaScript is and how it’s used. Now, let’s move on to understanding SEO and how it connects to JavaScript.
What is SEO?
Search Engine Optimization (SEO) involves a set of strategies and practices aimed at improving the visibility of a website in search engine results pages (SERPs).
Unlike paid advertising, where businesses pay for their placement, SEO is about earning that spot organically. This is done by optimizing various aspects of your website to align with what search engines like Google look for when deciding which sites to show first.
Why is SEO Important?
SEO is crucial because it drives organic traffic to your website, which is often considered the most valuable kind. Why? It’s because these visitors are actively searching for what you offer.
A higher ranking in search results leads to greater visibility. This, in turn, can lead to more traffic, credibility, and trust from users. When your site appears at the top of the search results, users are more likely to see your brand as authoritative and trustworthy.
Moreover, SEO is cost-effective compared to paid advertising. Once your website is well-optimized, it can continue to attract traffic without the need for ongoing payments. This makes it a sustainable long-term strategy for online visibility and success.
How Does SEO Apply to Modern Websites?
Modern websites use SEO in multiple ways:
- On-Page SEO: This involves optimizing individual pages on your website to rank higher. Techniques include using relevant keywords, creating high-quality content, and ensuring the site is user-friendly with fast load times and mobile optimization.
- Off-Page SEO: This focuses on building the website’s authority through backlinks from other reputable sites. The more trustworthy sites that link to your content, the more credible your site appears to search engines.
- Technical SEO: This ensures that your website’s backend is well-organized, making it easier for search engines to crawl and index your site. It involves improving site speed, mobile responsiveness, and overall site architecture.
- Content Quality: Creating valuable, relevant content is at the heart of SEO. High-quality content that answers users’ queries effectively will not only rank higher but also keep visitors engaged, reducing bounce rates and increasing conversions.
- User Experience: SEO now extends to the overall experience of your website, including how easy it is to navigate and how quickly it loads. Google and other search engines prioritize sites that offer a good user experience.
What is JavaScript SEO?
JavaScript SEO refers to a specialized area of technical SEO focused on optimizing websites that rely heavily on JavaScript for rendering content.
Unlike traditional websites, which primarily use HTML and CSS to deliver content, JavaScript-powered websites generate or modify content dynamically on the client side (in the user’s browser) rather than on the server side.
This dynamic behavior can present challenges for search engine crawlers, which are traditionally more adept at indexing static content.
While search engines have improved their ability to execute JavaScript, they may not fully index content that relies on user interactions (like clicks) to become visible. This can lead to portions of your site being invisible to search engines, reducing your overall search visibility.
Challenges JavaScript Poses to Traditional SEO Practices
JavaScript introduces several challenges to traditional SEO practices:
Delayed Rendering
Since JavaScript requires additional processing by search engines to render the content, it can slow down the indexing process. This delay can lead to critical content not being indexed as quickly. Or, in some cases, your web page may not be indexed at all if the rendering process fails.
Content Duplication
JavaScript frameworks can inadvertently create multiple URLs for the same content (e.g., with or without trailing slashes, or different query parameters), leading to duplicate content issues. This can dilute your SEO efforts by spreading link equity across multiple URLs instead of consolidating it into one.
Blocked Resources
If JavaScript files or other resources are blocked by robots.txt or not properly linked, search engines might not fully crawl or index the site, leading to incomplete indexing.
How Search Engines Work with JavaScript
Search engines like Google handle JavaScript through a three-step process: crawling, rendering, and indexing. Understanding these steps is crucial for optimizing JavaScript-heavy websites.
Crawling
This is the initial step where search engine bots, often called crawlers or spiders, visit your website and read its content. For traditional HTML websites, the content is straightforward. But for JavaScript-heavy sites, crawlers need to execute JavaScript to fully understand the page content.
This means the bot fetches HTML, CSS, and JavaScript files and queues them for further processing.
Rendering
After crawling, the search engine must render the JavaScript. Rendering is when the search engine processes the JavaScript to generate the complete webpage as it would appear to a user.
This includes any dynamic content generated by JavaScript. Google uses a headless browser for this task, which mimics how a regular browser would execute the code.
Indexing
Once the page is rendered, the search engine analyzes the content and stores it in its index. This index is a massive database of web content that Google uses to retrieve relevant pages in response to search queries.
For JavaScript-rendered content, this step is crucial because if the content isn’t rendered, it might not be indexed.

Image source: Google website
Crawling vs. Rendering JavaScript Content
The key difference between crawling and rendering in the context of JavaScript is that crawling involves fetching the basic HTML and associated files, while rendering involves executing JavaScript to build the full webpage.
Crawlers can quickly gather HTML, but rendering JavaScript takes more time and resources. Therefore, pages that rely heavily on JavaScript might experience delays in being indexed if the rendering queue is long.
The Role of Googlebot in JavaScript SEO
Googlebot, Google’s web crawler, has evolved to handle JavaScript much more effectively than in the past. When Googlebot encounters a webpage, it first downloads the HTML and then queues the JavaScript files for rendering.
The rendering is done by a web rendering service (WRS). This service executes the JavaScript code to generate the complete, interactive version of the webpage, including any dynamic content.
During this process, Googlebot constructs the Document Object Model (DOM), which represents the structure of the webpage after JavaScript execution.
Once the DOM is fully rendered, Googlebot can parse and index all the content, including dynamically generated elements like text, images, and metadata.
This means that if your content is generated or modified by JavaScript, Googlebot can still see and index it as long as it can fully render the page.
Technical SEO for JavaScript Sites
There are two different approaches to how web pages are generated and displayed to users, and each has a significant impact on JavaScript SEO:
Server-Side Rendering (SSR)
In SSR, the content of a web page is rendered on the server before it is sent to the user’s browser.
When a user requests a page, the server processes all the necessary data and sends a fully-rendered HTML page to the browser. The user sees the content almost immediately, and search engines can easily crawl and index the content because it’s already in the HTML when it arrives at the browser.
SSR is generally better for SEO because search engines receive a fully rendered page. This makes it easier for them to crawl and index the content.
Client-Side Rendering (CSR)
In CSR, the server sends a minimal HTML page to the browser, which then uses JavaScript to fetch and render the rest of the content. This method relies heavily on the browser to build the page, which can lead to slower initial load times since the browser has to execute JavaScript before displaying the content.
While Server-Side Rendering (SSR) is excellent for SEO and initial page load performance, Client-Side Rendering (CSR) offers benefits that SSR alone cannot provide, particularly in terms of user experience and application interactivity.
It can also reduce server load and provide faster subsequent page loads in certain scenarios.
Balancing SSR and CSR
In many modern web applications, a hybrid approach is used where SSR is employed for the initial page load (to ensure quick loading times and SEO-friendliness), and CSR takes over for subsequent interactions, enhancing user experience and reducing server strain.
Dynamic Rendering for SEO
Dynamic rendering is a technique used to optimize JavaScript-heavy websites for search engines, particularly when traditional rendering methods cause problems with indexing and crawling.
It works by detecting when a search engine bot like Googlebot is trying to access your website and then serving a pre-rendered, static HTML version of your page to that bot.
Meanwhile, human users continue to see the fully dynamic, JavaScript-powered version of your site.
Should You Use Dynamic Rendering?
In general, dynamic rendering is seen as a temporary solution or a workaround, not a permanent fix.
Google still recommends using techniques like Server-Side Rendering (SSR) or hybrid approaches when possible. These methods are more sustainable and provide better long-term results for both SEO and user experience.
Most Common JavaScript Frameworks
When building websites, developers often use JavaScript frameworks like React, Angular, and Vue.js.
React
React is a JavaScript library developed by Facebook for building user interfaces, particularly single-page applications. Developers can create reusable UI components that manage their own state. This way, it’s easier to build complex user interfaces.
By default, React uses client-side rendering (CSR). But it also has strong support for server-side rendering (SSR) through frameworks like Next.js.
Angular
Angular is a comprehensive JavaScript framework developed and maintained by Google. It is a full-fledged framework, offering a range of features such as two-way data binding, dependency injection, and extensive tools for building large-scale applications.
Similar to React, Angular also leans heavily on client-side rendering, but it also has SSR capabilities through Angular Universal.
Vue.js
Vue.js is a flexible JavaScript framework that facilitates the creation of user interfaces and single-page applications. Created by Evan You, Vue.js is designed to be adaptable and can be used incrementally. You can start using it for just a part of your application and scale up as needed.
This JavaScript framework is known for its simplicity, flexibility, and ease of integration with other projects and libraries. It can also be set up for either client-side or server-side rendering.
Common JavaScript SEO Issues and Solutions
Duplicate Content and Canonicalization
Duplicate content occurs when identical or very similar content is accessible through multiple URLs on the same website.
This can confuse search engines, leading to the dilution of ranking power, as they struggle to determine which version of the content should be prioritized in search results.
So how does JavaScript cause duplicate content issues?
JavaScript can inadvertently create duplicate content issues by generating URLs with different parameters that point to the same content. Without proper handling, these different URLs can be seen by search engines as separate pages with duplicate content.
As an example, imagine your visitors going to your store website. After adding an item to their cart, the URL changes from store.com/shoes to something like store.com/shoes?session_id=12345.
Even though the content (the shoe page) is the same, search engines might think store.com/shoes and store.com/shoes?session_id=12345 are different pages. Without proper management, search engines could index both URLs, creating duplicate content.
Canonicalization is a process used in SEO to address duplicate content issues. It involves using a canonical tag (rel=”canonical”) to indicate the preferred version of a page when there are multiple versions available.
This tag helps search engines understand which version of the content is the “official” one that should be indexed and ranked.
How to Fix Duplicate Content and Canonicalization Issues
You can establish a canonical URL for duplicate or extremely similar sites in Google Search using a variety of approaches. These are, in order of their strength in influencing canonicalization:
Redirects
Redirects are a clear indication that the target of the redirect should become canonical. You can use redirects to tell Googlebot that the redirected URL is superior to the original URL. You should use this exclusively when removing a duplicate page.
Using rel=”canonical” Link Annotations
You can use rel=”canonical” link annotations to indicate that the supplied URL should become canonical
The rel=”canonical” link element method allows you to add a <link> element in the code for all duplicate pages, pointing to the canonical page. However, this only applies to HTML pages and not to formats like PDF. In such circumstances, use the rel=”canonical” HTTP header.
As an example, if you want the site https://store.com/shoes to be your canonical URL even though there are many variants of URL that can access this content, you can do so by doing what’s shown below.
<html>
<head>
<title>Check out our new collection of shoes</title>
<link rel="canonical" href="https://store.com/shoes" />
<!-- other elements -->
</head>
<!-- rest of the HTML -->
Include a Sitemap
You can specify your canonical pages in a sitemap. This can be easy to do and maintain and can be beneficial, especially on large sites. But it’s a weaker signal to Google than the rel=”canonical” mapping technique.
Google must still find the related duplicate for any canonicals you specify in the sitemap.
Do note that these methods work best when they are combined, so we encourage you to give all of these methods a try.
Best Practices for Canonical Tags for Better JavaScript SEO
- Do not utilize the robots.txt file for canonicalization purposes.
- Don’t define various URLs as canonical for the same page using different canonicalization techniques (for example, don’t specify one URL in a sitemap but a different URL for the same page using rel=”canonical”).
- Do not use the URL removal tool for canonicalization. It conceals all URL variants from Search.
- It’s not advisable to use the noindex tag to manage canonical page selection within a single site, as this would remove the page entirely from search engine results. The preferred option is to use rel=”canonical” link annotations.
- When linking within your site, use the canonical URL rather than the duplicate URL. Linking to the URL you believe to be canonical helps Google understand your preference.
- If you use hreflang elements, make sure to include a canonical page in the same language, or the best available substitute language if one does not exist.
Challenges with Hash-Based Routing (#)
When you see a # in a URL, like example.com/#section1, that # is used by browsers to jump to a specific part of the same page, like a table of contents or a section further down. It’s a built-in function of browsers, and anything after the # usually isn’t sent to the server when the page is requested.
However, some JavaScript developers have started using # for other things, like navigating between different pages or adding extra data to the URL. While this might work technically, it can cause confusion and problems.
Why It’s a Problem
- Browsers Ignore the Rest: When you use # in a URL, the server ignores everything after it. This can mess up how the page is processed or how data is handled.
- Confusing to Manage: Since # is meant for one thing (jumping to parts of a page), using it for something else can make your website harder to manage and can confuse both developers and the systems handling your website.
Better Alternatives
For example, if you’re using the Vue.js framework, developers often use # to manage how the website navigates (this is called routing). Instead of using #, it’s better to use something called ‘History Mode,’ which creates clean URLs without #.
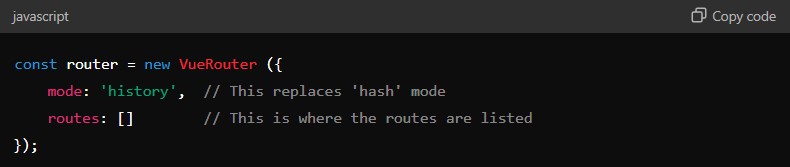
By using History Mode, the URLs on your site will look cleaner (like example.com/page1 instead of example.com/#page1), and it avoids the issues that come with misusing the #.
Lazy Loading and SEO
Lazy loading is a web development technique that delays the loading of non-essential content, like images and videos, until they are needed.
If not implemented correctly, lazy loading can prevent search engines from indexing content that is loaded later, such as images or text that appear only after scrolling. This might cause important content to be missed during the crawling process, which can hurt your SEO.
How to Fix Lazy-Loaded Content
Ensure that all important content is loaded when it becomes visible on the screen (the viewport). This makes sure Google can see it, as Google’s crawler doesn’t interact with your page like a user would.
- Built-in Browser Lazy Loading: Modern browsers have built-in support for lazy loading images and iframes.
- IntersectionObserver API: This API allows you to detect when elements enter the viewport and load them accordingly. It can be best described using the example below.
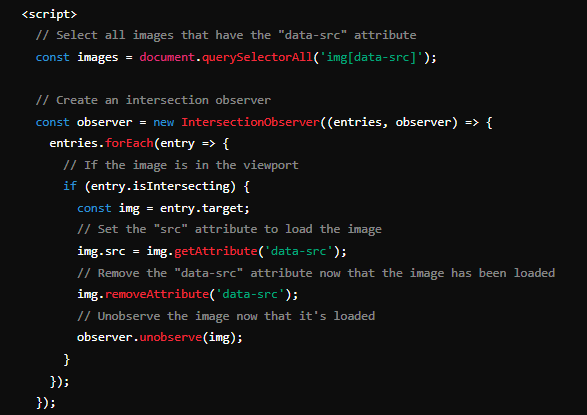
- JavaScript Libraries: Some libraries are specifically designed to load content when it enters the viewport, without needing user actions like scrolling.
- Avoid Lazy Loading Critical Content: Don’t apply lazy loading to content that is immediately visible when the page loads. This content needs to be prioritized and should be seen by both users and search engines.
Lastly, always test your lazy loading setup to ensure that it works correctly and that Google can load all your content. One way of doing so is by using the URL Inspection Tool in Google Search Console
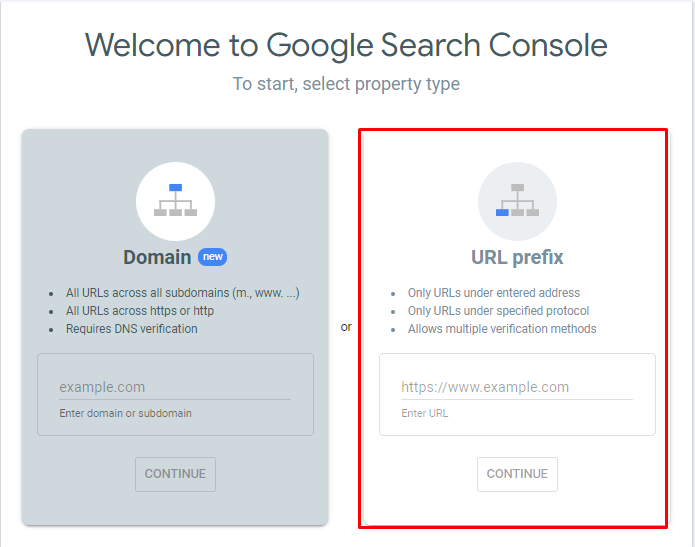
Best Practices for JavaScript SEO
Make Your Website More Accessible
When designing your website, focus on making it accessible to all users, not just search engines. Consider the needs of people who might not be using a browser that supports JavaScript, like those who rely on screen readers or have older mobile devices.
A simple way to check your site’s accessibility is by turning off JavaScript in your browser or viewing it in a text-only browser like Lynx. This approach helps you spot any content that might be hard for Google to read, such as text that’s embedded in images.
To turn off JavaScript in Google Chrome, open the browser, click the three dots in the top-right corner, and go to “Settings.” On the left side of the screen, click “Privacy and security,” then click on “Site Settings.” Under the “Content” section, find “JavaScript” and toggle it to “Don’t allow sites to use JavaScript.”

Infinite Scrolling
If you’re using infinite scroll on your website, it’s important to also include paginated loading.

Paginated loading helps users share specific sections of your content and makes it easier for them to return to those sections later. It also allows Google to link directly to a specific part of the content, instead of just the top of the page.
To enable this, make sure each section of your content has a unique link that users can share and access directly. Use the History API to update the URL as new content loads dynamically.
Create Unique Titles and Descriptions for Your Pages
Having unique and descriptive <title> elements and meta descriptions helps users quickly find the best match for their search. You can use JavaScript to set or change these elements.

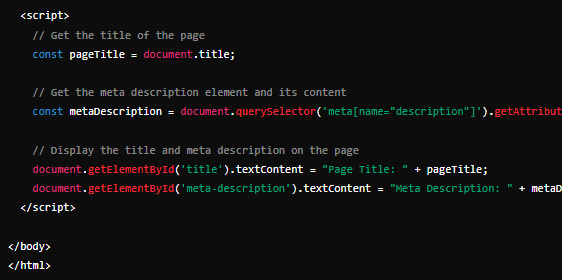
Title Links
The title link is what users see in search results. Although Google may generate this title link automatically, you can influence it by following best practices.
- Make sure every page on your site has a specific title in the <title> element.
- Keep your titles descriptive but concise. Avoid vague terms like “Home” or “Profile” and don’t make the titles too long, as they might get cut off in search results.
- Don’t overuse keywords. While it’s good to include some descriptive terms, avoid repeating the same words multiple times.
Snippets
Snippets are short previews of your page’s content that appear in search results. Google may use the meta description tag to create these snippets if it provides a clearer summary than the content on the page.
It’s important to write unique descriptions for each page. Using the same description on every page isn’t helpful for users. Focus on creating accurate descriptions for individual pages, especially your homepage and most important pages. If you can’t write descriptions for every page, prioritize the most critical ones.
Write Compatible Code
When you write JavaScript code for your website, it’s important to make sure it works on all browsers and that Google can understand it. JavaScript is always changing and getting new features. But not all browsers, even Google can support every new feature right away.
If your code isn’t compatible with the browsers your users are on, parts of your website might not work correctly, or at all. Also, if Google can’t understand your code, your site might not show up properly in search results.
How to Make Sure Your Code Works Everywhere:
- Understand Browser Compatibility: Different browsers like Chrome, Firefox, or Safari might not all support the latest JavaScript features or APIs. To write compatible JavaScript code across all browsers, focus on using standardized features supported by the latest ECMAScript (ES) specifications and avoid browser-specific code. You can ensure compatibility by testing your code in multiple browsers and using tools like Babel to transpile modern JavaScript into versions supported by older browsers.
- Use Polyfills: A polyfill is like a backup plan. If a browser doesn’t support a feature your code needs, a polyfill provides an alternative way to make that feature work. It’s like giving older browsers a cheat sheet so they can understand newer JavaScript.
- Use Differential Serving: This means giving different versions of your code to different browsers based on what they can handle. Modern browsers might get the latest and greatest version, while older ones get a simpler version they can understand.
- Check for Limits: Not every browser feature can be poly-filled. Some things just won’t work on older browsers no matter what. So, it’s important to check the documentation to understand what can and can’t be made compatible.
Use the Correct HTTP Status codes
When you visit a webpage, your browser and the server hosting the webpage communicate using something called HTTP status codes. These codes are like messages that tell the browser or Google’s web crawler what happened when trying to load the page.
Googlebot uses these status codes to understand if there were any issues when it tried to access a page on your website. Depending on the status code, Googlebot will know if it should make your page searchable or if there is a problem.
Using the correct status codes helps ensure that Google and other search engines understand what’s happening with your pages. This way, Google can index your site correctly, and users won’t run into issues like broken links or pages that don’t exist anymore.
Key HTTP Status Codes You Should Know
404 – Page Not Found: This code tells Googlebot and browsers that the page doesn’t exist. If someone tries to visit a URL that doesn’t exist anymore, the server will send a 404 code. Googlebot then knows not to index this page.
401 – Unauthorized: This code is used when a page is behind a login screen. It tells Googlebot that it needs special permission to view the page. In other words, the server requires the client (such as a browser or application) to authenticate itself before accessing the requested resource. Googlebot won’t be able to index these pages unless access is granted.
301 – Moved Permanently: If you’ve moved a page to a new URL, you use this code to tell Googlebot that the page has been permanently moved. This helps Google update its index with the new URL so users can find the right page.
Avoid Soft 404 Errors in Single Page Apps
When you build a single-page app using JavaScript, the entire app runs on one web page. JavaScript handles the navigation to moving between different pages of content.
A soft 404 error happens when a page that should show a “not found” message (like when a product doesn’t exist) instead shows a normal page with a message like “No product found” but still returns a status code that says everything is okay (like 200). This confuses search engines like Google, which might think the page is valid when it really isn’t.
How To Avoid Soft 404 Errors
1. JavaScript Redirect to a 404 Page:
If a product or page doesn’t exist, you can use JavaScript to redirect users to a dedicated “not found” page that properly returns a 404 status code.
Example:

2. Add a Noindex Tag
If redirecting isn’t possible, another approach is to add a meta tag that tells search engines not to index the error page, so it doesn’t show up in search results.
Example:

Allow Crawling of JavaScript Files for JavaScript SEO
When it comes to JavaScript SEO, it’s important to make sure that search engines like Google can access all the files they need to properly display your webpage.
Allowing Google to crawl your JavaScript and CSS files is crucial because it ensures that your website is rendered correctly in search results. If Google can’t see these files, parts of your page might be missing or displayed incorrectly, which can negatively impact your SEO.
How to Allow Google to Crawl JavaScript Files
1. Update Your robots.txt File
The robots.txt file tells search engines which parts of your website they are allowed to access. To make sure Google can access your JavaScript and CSS files, you need to add the following lines to your robots.txt file:

2. Check Subdomains and Other Domains
If your website uses resources from other subdomains (like an API) or external domains, you need to make sure those robots.txt files also allow access to the necessary JavaScript and CSS files. If these resources are blocked, it can cause problems with how your site is displayed in search results.
3. Test Using the Network tab
You can test whether blocking certain resources affects your page’s content by using the Network tab in Chrome DevTools. Block the specific file, reload the page, and see if anything changes. If blocking the file causes issues, that file should be accessible to Google.
Use Structured Data
Structured data is a specific format that provides information about a page and classifies the page content. This structured data can be included in your pages using a format called JSON-LD.
JSON-LD (JavaScript Object Notation for Linked Data) is a way to encode structured data in a format that search engines like Google can read and understand. It helps search engines understand the context of your content, such as identifying a page as a recipe, an article, a product, etc.
Why This Matters for JavaScript SEO
Properly implemented structured data can enhance how your pages appear in search results, often leading to rich results like enhanced listings with stars, images, and other visual elements.
By using JavaScript to manage this data, you keep your site flexible and dynamic, while still providing search engines with the information they need to rank your content effectively.
Using JavaScript to Inject JSON-LD
You can use JavaScript to create and add this structured data (JSON-LD) directly to your webpage. Follow the steps below to do so.
1. Generate JSON-LD with JavaScript: Write a JavaScript script that creates the JSON-LD structured data for your page.
2. Inject JSON-LD into the Page: Use JavaScript to insert the generated JSON-LD into your page, typically within a <script type=”application/ld+json”> tag.

3. Test Your Implementation: It’s crucial to test your structured data to make sure it’s working correctly. Google provides tools like the Rich Results Test where you can check if your JSON-LD is being read and interpreted correctly by search engines.
Tools to Test How Googlebot Sees Your JavaScript Content
Several tools can help you understand how Googlebot interacts with and indexes your JavaScript content:
Google Search Console’s URL Inspection Tool
The URL Inspection tool in Google Search Console is a powerful tool that helps you see what Google knows about a specific page on your site. This is especially useful for troubleshooting issues related to JavaScript SEO.
You can use the URL Inspection Tool to:
- Troubleshoot Missing Pages: If a page on your site isn’t appearing in Google’s search results, you can use this tool to find out why. It tells you whether Google has crawled and indexed the page or if there’s a problem preventing it from showing up.
- Check Fixes: After fixing an issue on a page like a JavaScript problem or an indexing error, you can use the tool to verify that the fix worked.
- Request Indexing: If you’ve just added or updated a page, you can ask Google to crawl and index it right away, rather than waiting for Google to find it on its own.
How to Use the URL Inspection Tool:
I. Inspect a Page:
- Type the full URL of the page you want to inspect into the search bar at the top of Google Search Console.
- Or, click the inspect icon next to a URL in one of your reports.
II. Check the Page Status:
- URL is on Google: This means the page is indexed and there are no major issues.
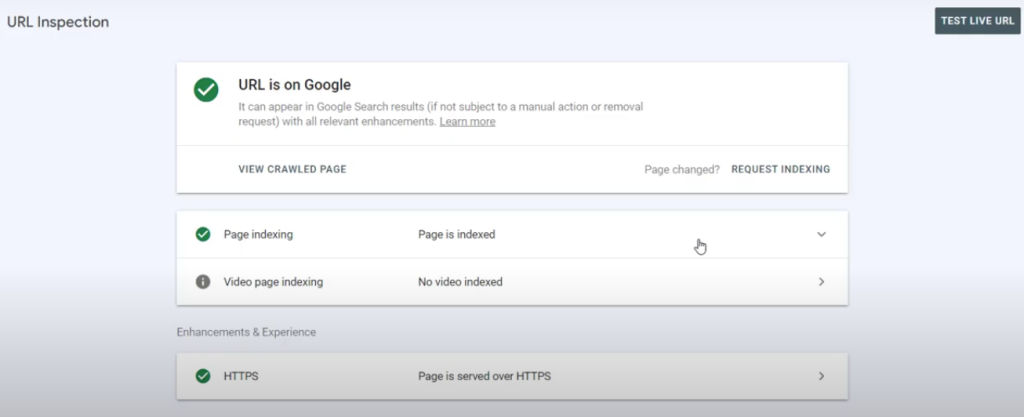
- URL is on Google, but has issues: The page is indexed, but there are problems that could affect its performance in search results. The tool will show you what those issues are.
- URL is not on Google: This means the page isn’t indexed. The tool will help you understand why, whether it’s due to crawl issues, indexing blocks, or duplication with another page.
III. Fix and Recheck:
- If you find a problem, fix it on your site.
- Then, use the tool to “Test live URL” and confirm the issue is resolved.
- If everything looks good, click “Request indexing” to ask Google to re-index the page.
Rich Results Test
As mentioned previously, the Rich Results Test is a tool provided by Google to help you check if your webpage is eligible for special features in Google Search results, often called “rich results.”
Using the Rich Results Test ensures that your structured data is set up correctly so that Google can display rich results for your pages. These features might include things like star ratings, images, or other enhanced information that makes your search listing stand out.
The Rich Results Test supports several formats for structured data, including JSON-LD, RDFa, and Microdata. JSON-LD is the most common and recommended format for JavaScript SEO because it is easy to implement and works well with JavaScript.
How to Use the Rich Results Test
1. Testing a URL
Enter the full URL of the page you want to test. Make sure that all resources on the page (like images, scripts, and structured data) are accessible to anyone on the internet, not just users who are logged in or behind a firewall.
If your page is on a local machine or behind a firewall, you can still test it by exposing it using a tool that creates a secure tunnel.
2. Testing a Code Snippet
Instead of testing a full page, you can also test a piece of code. On the tool’s main page, select “Code” instead of “URL,” paste your code snippet, and run the test. You can modify the code and run the test multiple times to see how changes affect the results.
3. Choosing a User Agent
A user agent is the system (like a smartphone or a desktop computer) that Google uses to browse your page. By default, Google uses a smartphone user agent because most people access websites via mobile devices. However, you can choose to test with a desktop user agent if needed.
It’s generally recommended to use the smartphone option since it aligns with Google’s mobile-first indexing approach.
Reviewing the Results
After running the test, you’ll see which types of rich results were found on the page and any errors or warnings related to your structured data. If there are issues, you can click on them to see more details and even view the specific part of your code that needs fixing.

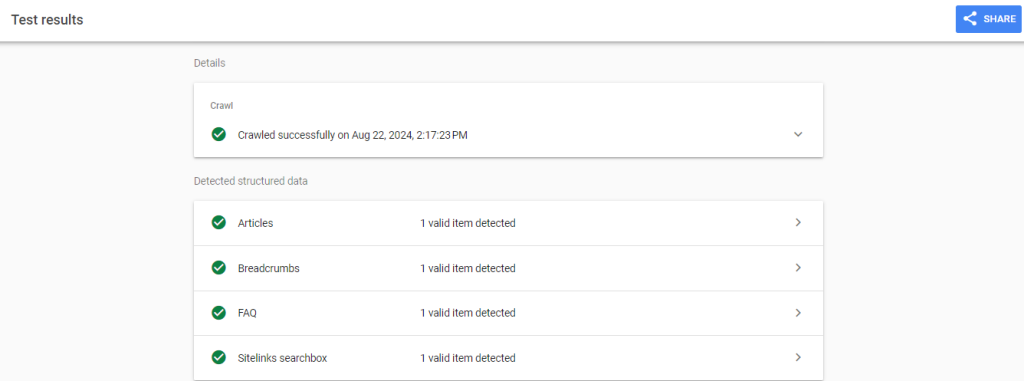
As an important tip, make sure there are no comments within your JSON-LD code. While the Rich Results Test tool ignores them, they might cause potential issues when your page goes live.
Lighthouse

Image Source: Google
As part of Chrome’s Developer Tools, Lighthouse provides an SEO audit that includes checking whether JavaScript content is correctly rendered and indexed. It also gives insights into performance issues that might affect how Googlebot renders your page.
Lighthouse can run in different programs. It can be through Chrome DevTools, from the command line, from a web UI, or as a node module.
Lighthouse is also open-source, and contributions from developers are highly encouraged.
Web Design Strategies for Better JavaScript SEO
Progressive Enhancement
Progressive enhancement involves building a website by starting with a basic, functional version that works on all browsers, including those with limited capabilities. Then, you layer on more advanced features like JavaScript.
For JavaScript SEO, progressive enhancement ensures that the core content of your website is accessible to all users, including search engines, even if JavaScript fails or is not supported by the browser.
Search engines like Google may not fully render JavaScript when first crawling a page, so having a solid, HTML-based foundation helps ensure that the essential content is indexed properly.
Graceful Degradation
Graceful degradation, on the other hand, takes the opposite approach. It starts by creating a fully-featured version of a website using the latest technologies. Then, as the site is accessed on older or less capable browsers, it degrades by removing features that aren’t supported, ensuring the site still functions, albeit with fewer features.
In terms of JavaScript SEO, graceful degradation helps ensure that your site remains functional and accessible even if some of the JavaScript features don’t work.
Both strategies ensure that all users and search engines can access your content, regardless of the browser or device they are using.
FAQs About JavaScript SEO
No, JavaScript is not inherently bad for SEO, but it does require additional steps to ensure that content is accessible and indexable by search engines.
Minify and compress JavaScript files, use asynchronous loading, and implement lazy loading where appropriate to improve page load times.
Yes, Google can index dynamically loaded content, but it may not always be successful. Using techniques like SSR or pre-rendering can help ensure that content is properly indexed.
Pre-rendering involves generating a static version of your website’s pages that can be served to search engines, making it easier for them to crawl and index the content.
Page load time is a ranking factor for SEO. Faster-loading pages provide a better user experience and are favored by search engines, so optimizing JavaScript to load efficiently is crucial.
With mobile-first indexing, Google primarily uses the mobile version of a site for indexing and ranking. Ensuring that JavaScript content is mobile-friendly and fully accessible is crucial for SEO.
Canonical tags tell search engines which version of a page should be considered the original, preventing duplicate content issues. This is important when JavaScript generates multiple similar URLs for the same content.
Yes, JavaScript can generate and inject structured data into web pages.
Wrapping Things Up
Although JavaScript can be challenging for SEO, it’s a powerful tool that, when optimized, can greatly improve your site’s visibility and user experience.
If you’re new to JavaScript SEO, the information above may be overwhelming. But don’t worry, you can start with small, manageable steps and gradually build your knowledge and skills.
By applying the strategies in this guide, you can make sure that your website content is search engine-friendly and engaging for your audience. And with the right approach, you will see your website rise in search engine rankings in no time.